10 مورد از مهمترین الگوریتمهای یادگیری ماشین

یادگیری ماشین (Machine Learning) به سرعت در حال تغییر شکل دنیای فناوری و کسبوکارهاست. انتخاب الگوریتم مناسب بخش مهمی از فرآیند تجزیه و تحلیل دادهها است، زیرا هر الگوریتم گردآوری، پردازش و تحلیل دادهها را به روشهای مخصوص به خود انجام میدهد. در این وبلاگ، با ۱۰ مورد از مهمترین و کاربردیترین الگوریتمهای یادگیری ماشین آشنا خواهیم شد که میتوانند به شما در بهبود قابلیتهای تحلیلی و پیشبینی کمک کنند.
یادگیری ماشین چیست؟
قبل از بررسی مهمترین الگوریتمهای یادگیری ماشین، بیایید چیستی این مفهوم را زیر ذره بین قرار دهیم. یادگیری ماشین یکی از مباحث داغ و پر اهمیت دنیای هوش مصنوعی به حساب میآید. اگر ما سیستمهای کامپیوتری را طراحی کنیم که میتوانند همچون انسان فکر کنند و تصمیم بگیرند، از یادگیری ماشین استفاده کردهایم.
یادگیری ماشین یا ML یکی از تکنیکهای پر اهمیت دنیای هوش مصنوعی به حساب میآید که کاربردهای زیادی دارد. خیلی از کسب و کارهای نوین از تکنیکهای یادگیری ماشین برای توسعه تجارت یا جذب مشتریان جدیدتر استفاده میکنند.
انواع الگوریتمهای یادگیری ماشین
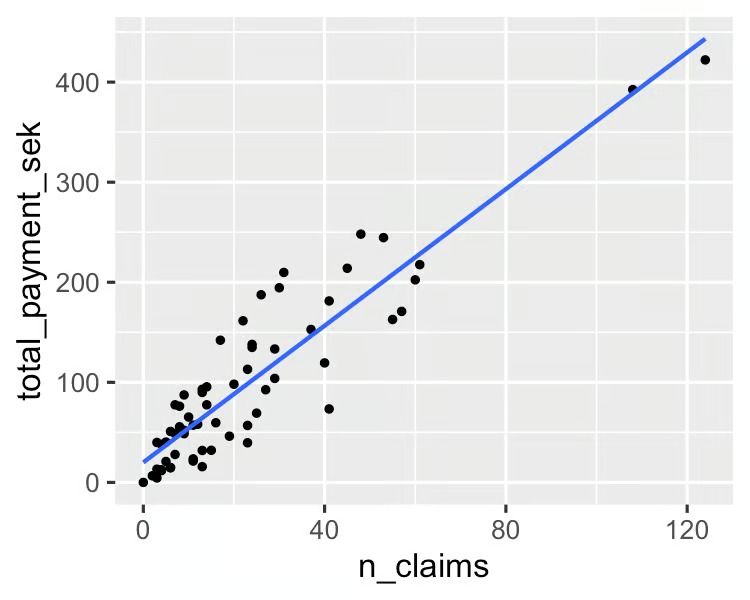
۱. رگرسیون خطی (Linear Regression)
مفهوم:
رگرسیون خطی یکی از سادهترین و پرکاربردترین الگوریتمها برای پیشبینی مقادیر پیوسته است. این الگوریتم با استفاده از معادله خطی، رابطه بین یک یا چند متغیر مستقل (features) و یک متغیر وابسته (target) را مدلسازی میکند.
کاربردها:
از این الگوریتم معمولاً برای پیشبینی فروش، قیمت مسکن و سایر مقادیر پیوسته استفاده میشود.
نکات مهم:
- فرضیات اصلی این الگوریتم شامل خطی بودن، همسانی واریانس و عدم وجود خودهمبستگی است.
- در صورت عدم تأمین این فرضیات، ممکن است دقت پیشبینی به میزان قابل توجهی کاهش یابد.

۲. رگرسیون لجستیک (Logistic Regression)
مفهوم:
رگرسیون لجستیک برای پیشبینی دو دسته (طبقهبندی باینری) طراحی شده است. این الگوریتم با استفاده از تابع سیگموئید، احتمال وقوع یک رویداد را محاسبه میکند و بسته به آستانهی تعیینشده، دستهبندی میکند.
کاربردها:
این الگوریتم بهطور وسیع در حوزههای پزشکی (تشخیص بیماری) و بازاریابی (شناسایی مشتریان بالقوه) استفاده میشود.
نکات مهم:
- این الگوریتم باید با دقت بالایی بر روی دادهها مورد ارزیابی قرار گیرد تا از وجود چندخطی (multicollinearity) یا عدم تجانس (heteroscedasticity) مطمئن شوید.
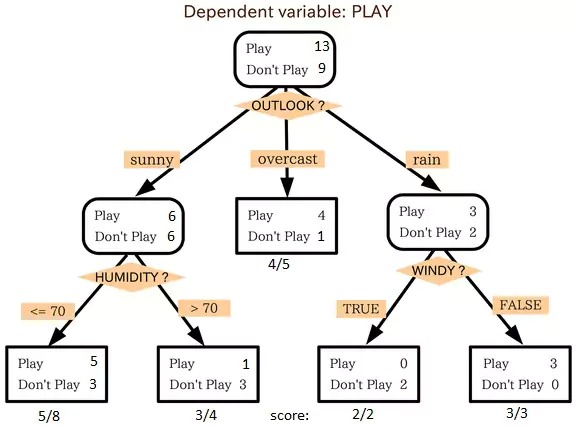
۳. درخت تصمیم (Decision Tree)
مفهوم:
درخت تصمیم یک ساختار درختی است که برای طبقهبندی و همچنین رگرسیون استفاده میشود. این الگوریتم دادهها را با استفاده از عبارات شرطی تقسیم میکند تا به تصمیم نهایی برسد.
کاربردها:
این الگوریتم مناسب برای مسائل طبقهبندی در زمینههایی مانند تشخیص تقلب و ارزیابی اعتبار میباشد.
نکات مهم:
- درختهای تصمیم ممکن است دچار اورفیتینگ (overfitting) شوند، بنابراین استفاده از تکنیکهایی مانند “کاهش عمق” (pruning) پیشنهاد میشود.
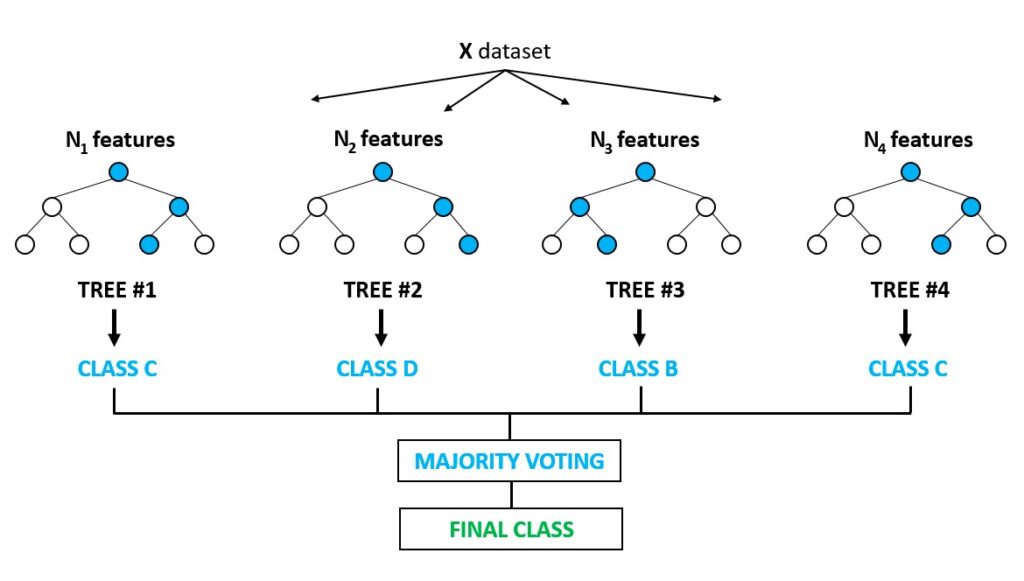
۴. جنگل تصادفی (Random Forest)
مفهوم:
جنگل تصادفی یک الگوریتم تقویتشده است که از ترکیب چندین درخت تصمیم مستقل برای ایجاد یک مدل قوی و پایدارتر استفاده میکند.
کاربردها:
این الگوریتم در تحلیل دادههای غیرخطی و مؤثر در جلوگیری از اورفیتینگ کاربرد دارد و در پیشبینیهای مالی و بیماریها بسیار محبوب است.
نکات مهم:
- جنگل تصادفی دقت بالایی دارد اما زمان محاسباتی بیشتری نسبت به درخت تصمیم صرف میکند.
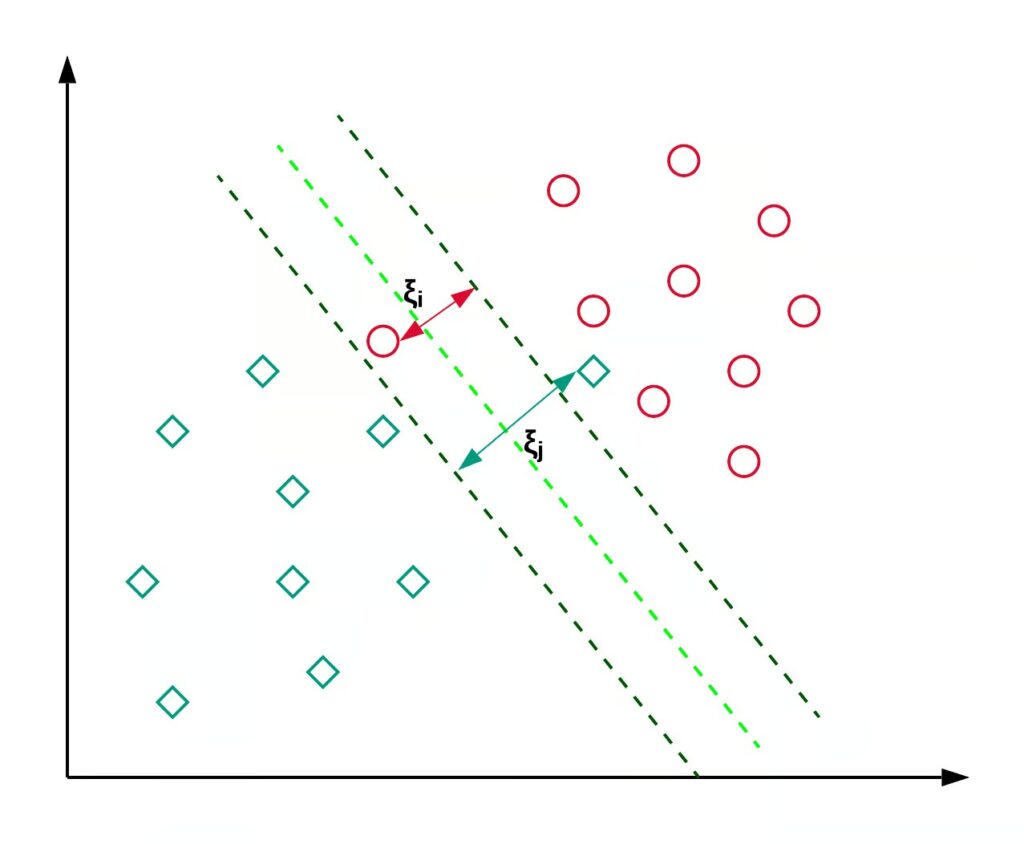
۵. ماشینهای بردار پشتیبان (Support Vector Machines – SVM)
مفهوم:
SVM یک الگوریتم مبتنی بر الگوی تفکیک است که با هدف پیدا کردن بهترین مرز (hyperplane) برای جداسازی کلاسهای مختلف طراحی شده است.
کاربردها:
SVM برای مسائل پیچیدهای مانند شناسایی تصویر و تشخیص الگوها کاربرد دارد.
نکات مهم:
- استفاده از هستههای مختلف (kernels) به این الگوریتم این امکان را میدهد که پیچیدگی دادهها را بهخوبی مدیریت کند.
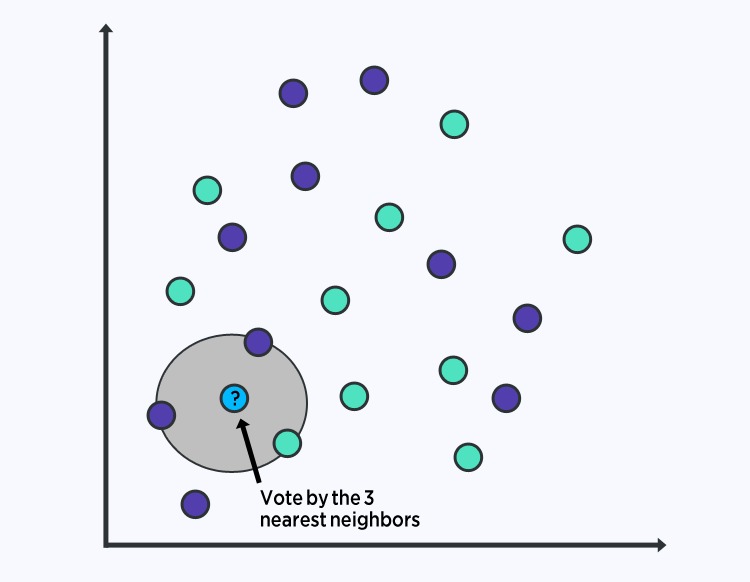
۶. الگوریتم k نزدیکترین همسایه (k-Nearest Neighbors – k-NN)
مفهوم:
k-NN یک الگوریتم غیرپارامتریک است که در آن طبقهبندی بر اساس نزدیکترین نمونهها (neighbors) به داده ورودی انجام میشود.
کاربردها:
این الگوریتم برای مسائل طبقهبندی در سیستمهای توصیهگر، تشخیص چهره و پزشکی مورد استفاده قرار میگیرد.
نکات مهم:
- انتخاب مقدار k مناسب بسیار مهم است و آزمایشات متعدد برای تعیین بهترین مقدار k پیشنهاد میشود.
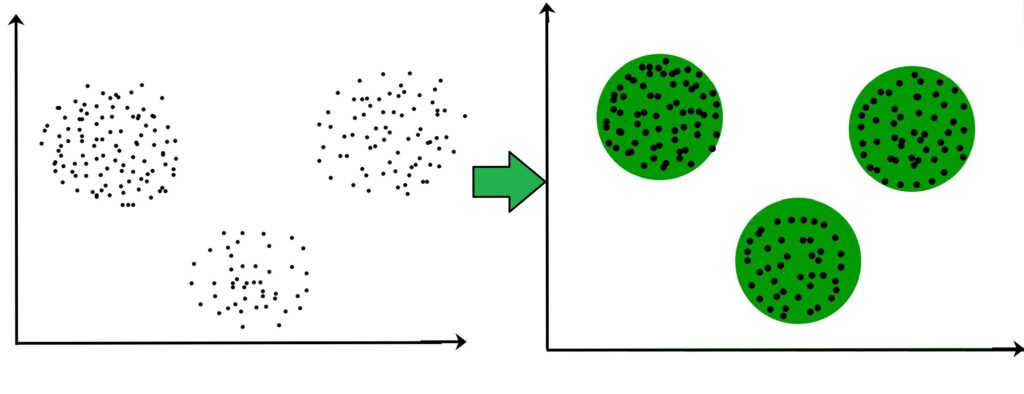
۷. خوشهبندی (Clustering Algorithms)
مفهوم:
خوشهبندی یک روش غیرنظارت شده برای تقسیمبندی دادهها به گروههای مشابه است. K-means یکی از رایجترین الگوریتمهای خوشهبندی است.
کاربردها:
این الگوریتم در تحلیل بازار، تقسیمبندی مشتریان و شناسایی الگوها بسیار کاربرد دارد.
نکات مهم:
- انتخاب تعداد خوشهها (k) میتواند چالشبرانگیز باشد و استفاده از روشهایی مانند “روش Elbow” میتواند کمککننده باشد.
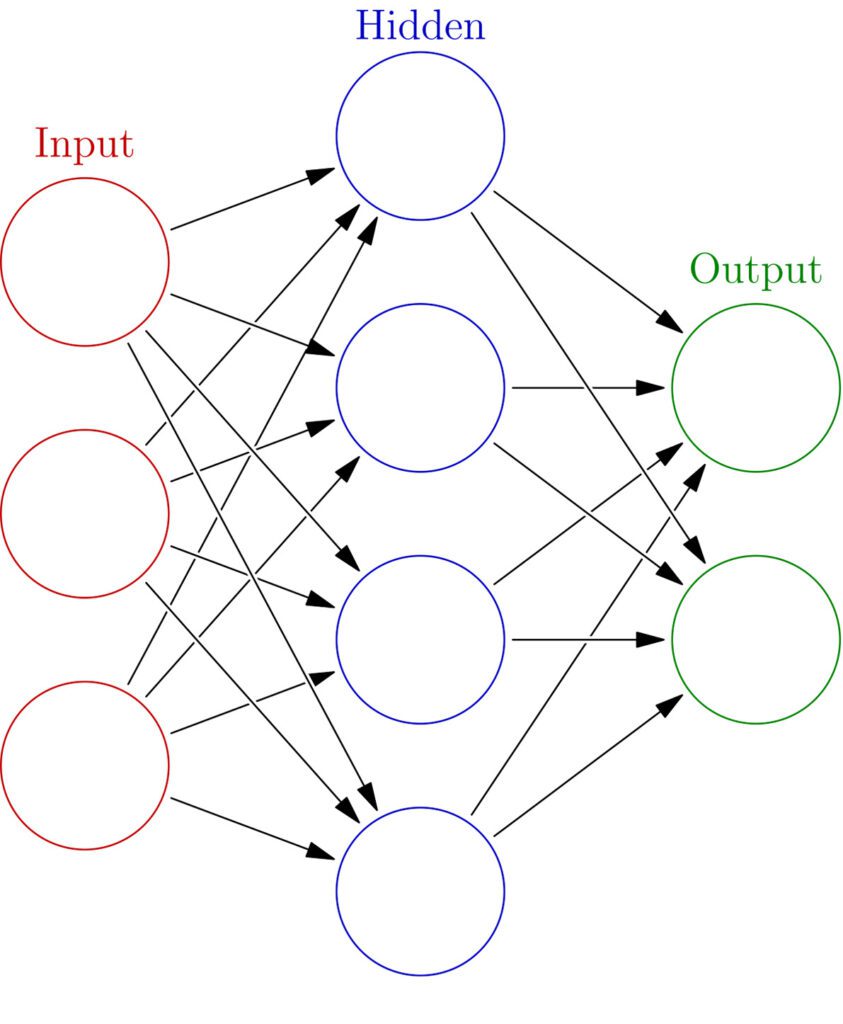
۸. شبکههای عصبی (Neural Networks)
مفهوم:
شبکههای عصبی مانند مغز انسان عمل میکنند و بهمنظور شناسایی الگوها، پردازش تصویر و پردازش زبان طبیعی مورد استفاده قرار میگیرند.
کاربردها:
این الگوریتمها در خودرانها، ترجمه زبان و شناسایی تصویر بهطور گستردهای کاربرد دارند.
نکات مهم:
- از جمله چالشهای استفاده از شبکههای عصبی، نیاز به دادههای فراوان و زمان آموزش طولانی است.
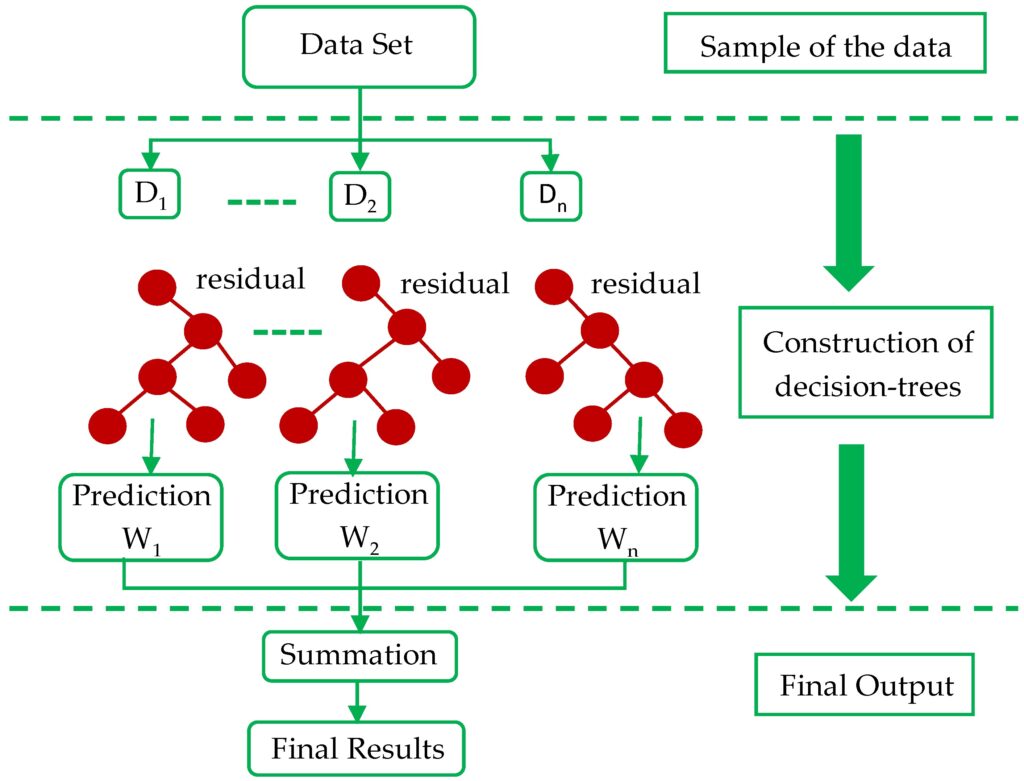
۹. الگوریتم XGBoost
مفهوم:
XGBoost یک الگوریتم تقویت کننده قوی است که به بهینهسازی سرعت و دقت مدلهای یادگیری ماشین پرداخته و معمولاً در مسابقات علمی و صنعتی به کار میرود.
کاربردها:
این الگوریتم بهویژه برای مسایل پیشبینی فروش، تشخیص تقلب و تحلیل مالی استفاده میشود.
نکات مهم:
- XGBoost با استفاده از تکنیکهای منحصربهفرد مانند کنترل بیشپیشرفت (overfitting) و نمایش اهمیت ویژگیها، به شدت کارآیی دارد.
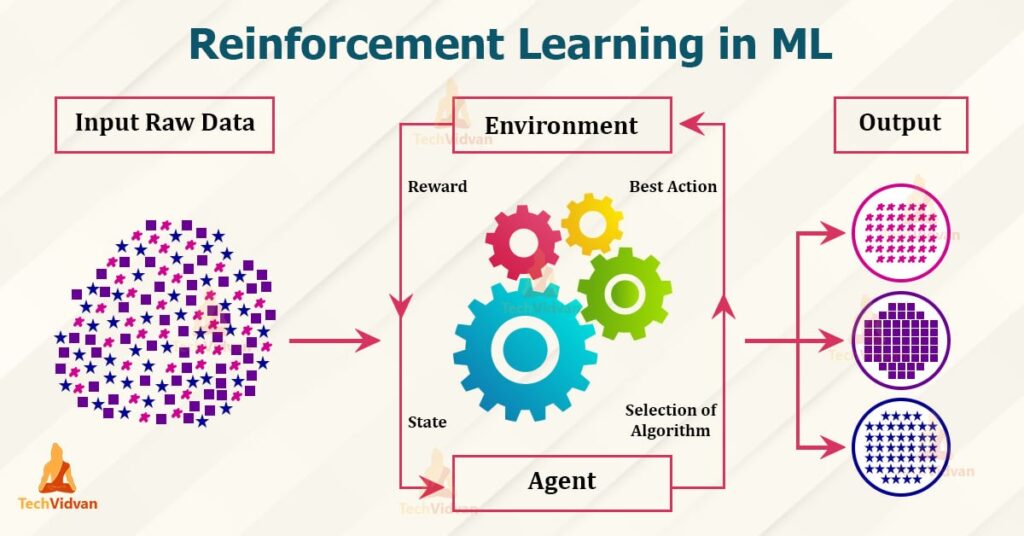
۱۰. یادگیری تقویتی (Reinforcement Learning)
مفهوم:
یادگیری تقویتی یک رویکرد یادگیری است که در آن مدلها با تعامل با محیط و دریافت پاداش یا تنبیه یاد میگیرند.
کاربردها:
از این الگوریتم در بازیهای دیجیتال، رباتیک و سیستمهای خودران استفاده میشود.
نکات مهم:
- چالش اصلی در یادگیری تقویتی، طراحی سیستم پاداش است که میتواند تأثیر زیادی بر روی یادگیری داشته باشد.
“دوره آنالیز داده و یادگیری ماشین ما، فرصتی است تا مهارتهای خود را در تحلیل دادهها تقویت کنید و به دنیای جدیدی از دانش وارد شوید.”
جهت آشنایی و ثبت نام دوره آنالیز داده و یادگیری ماشین اینجا کلیک کنید!
نتیجهگیری
یادگیری ماشین بهعنوان ابزاری قدرتمند در تجزیه و تحلیل دادهها، با الگوریتمهای متنوع و تخصصی خود به ما این امکان را میدهد که تصمیمات بهتری بگیریم و پیشبینیهای دقیقتری انجام دهیم. با انتخاب صحیح الگوریتم متناسب با نوع دادهها و مسأله مورد نظر، میتوان به نتایج بسیار بهتری دست یافت. حال که با ۱۰ مورد از مهمترین الگوریتمهای یادگیری ماشین آشنا شدید، امیدوارم این اطلاعات به شما کمک کند تا در پروژههای خود از این الگوریتمها بهطرز مؤثری استفاده کنید.






دیدگاهتان را بنویسید